
A few weeks ago, I awoke to a message from one of my friends
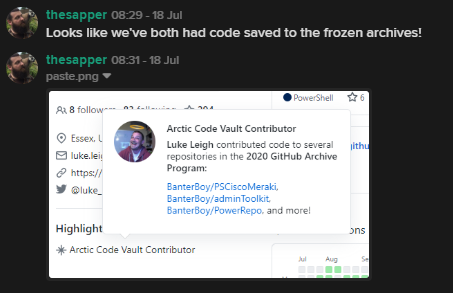
GitHub’s Arctic Code Vault is similar in nature to the Library of Alexandria, which was the most famous library of Classical antiquity. There have been a number of attempts to create a modern day Universal Library over the years but the most memorable for me was Google’s attempt which sadly ended under a storm of litigation. There are many articles written about this, with one of perhaps the saddest quotes I have heard in one of them
Somewhere at Google there is a database containing 25 million books and nobody is allowed to read them.
James Somer
GitHub created the “GitHub Archive Program” in 2019 with the idea of preserving the work of many opensource developers for future generations and ensuring it would be stored for many years to come….for at least 1,000 years.
The blog article from GitHub explains the process in much more detail than I have here but if you are not in the mood for some light reading they also have a TLDR video which will give you an insight into their incredible work.
GitHub have deposited archived data, 21TB of repository data to 186 reels of piqlFilm (digital photosensitive archival film), in a similar fashion to the Svalbard Global Seed Vault and is located down the road in a decommissioned coal mine.
I hope you take the time to read the additional links in the article. Whilst I was amused at the notion code I had written would be stored in the vault, having spent the time reading and understanding why they are doing this, I am somewhat humbled that my code will be around many years after I am gone.
In truth, it is a massive kick up the ass to make sure that it is properly formatted and documented so that it will at least make sense, should anyone ever be interested in what I have written.
Share on
Twitter Facebook LinkedInYou may also enjoy
The PowerShell Profile
How to improve your PowerShell user Environment. One of PowerShell’s most under-utilised admin assistants.

Hey people, I made a blog!
Erm….didn’t you just do that?
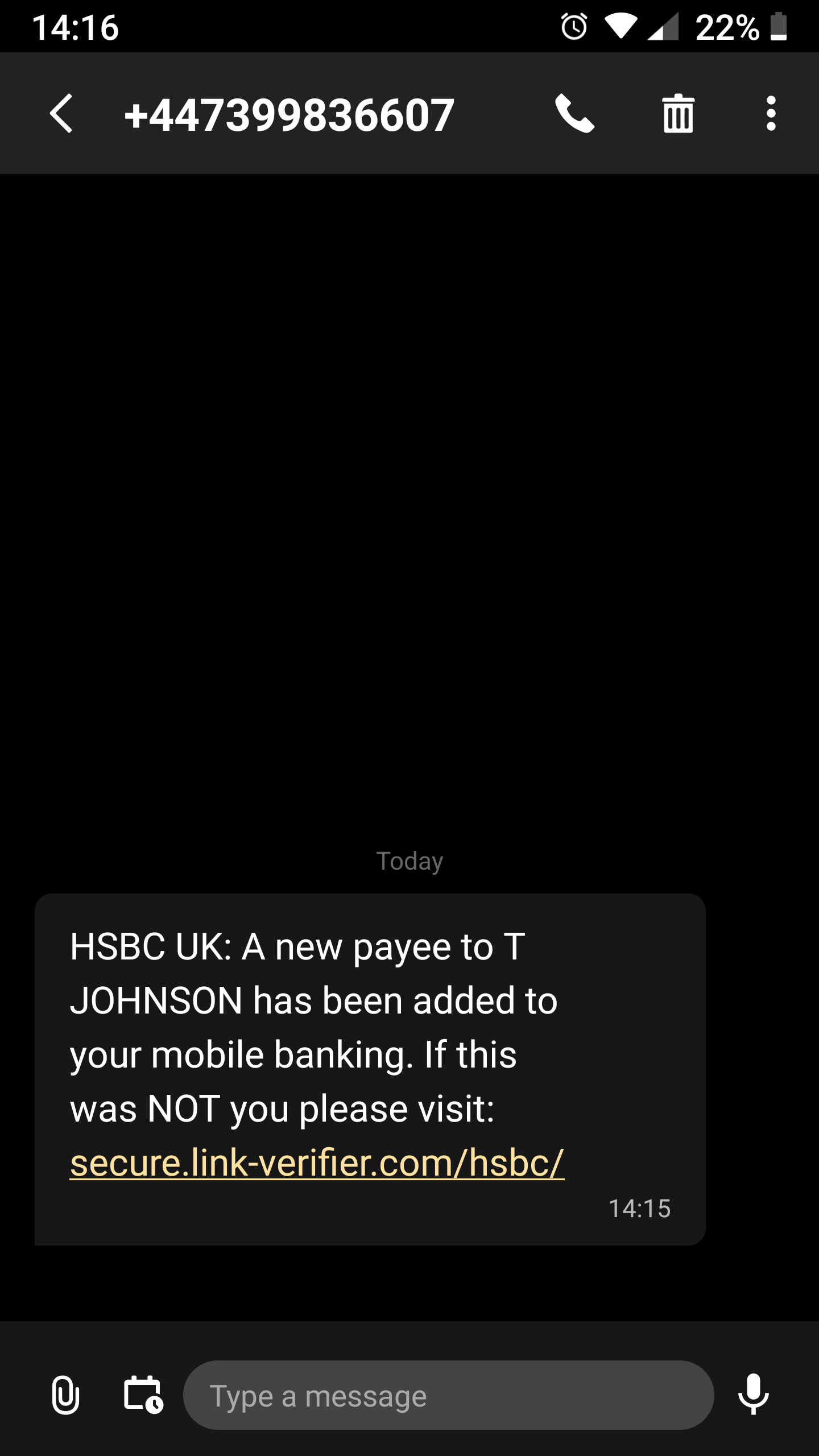
Text Alerts
Important message from the bank

Unwanted Parcels
Why you really need to protect your accounts